Fictional scenario: Forgetting what was wrongA multinational auditing company implemented an AI-driven system to automatically evaluate and rank CVs of job applicants. This system was trained on a diverse set of past applications, ensuring representation across gender, ethnicity and age. However, the landscape of the company’s operational requirements recently shifted significantly.
As part of its commitment to sustainability, the company adopted a new policy to only use public transportation system when reaching client companies or to conduct remote audits when public transport is not feasible. Consequently, holding a driving license ceased to be a relevant feature for job applications.
The company's management soon realised that the AI model's scoring criteria still considered the driver's licence as a relevant characteristic and was therefore excluding valuable candidates. Talented candidates who did not have a driver’s license were unfairly ranked lower, despite this no longer being relevant for the job.
Given that the AI model was already deployed across various countries and that a complete retraining of the model was impractical, the company decided to adjust the system to remove the impact of the driver’s license requirement.
Once the requirement for a driving licence had been removed from the AI model, the company verified that the system had correctly stopped taking this criterion into account when evaluating applications. Forgetting what was rightAn international research project in education involving over 100 different school districts developed an AI-based tool for English-as-a-second-language learning. The learning tool allows students to go through an array of personalised exercises, receive scores and immediate feedback on their answers, and get suggestions for useful learning materials.
Each district provided several datasets for model training, containing standardised test results across the participating districts, as well as audio files from oral assessments. However, midway through the project, School District A found itself in profound disagreement with the project’s new direction to also use the data for school comparisons. The school district feared this would lead to an oversimplified listing of ‘best’ and ‘worst’ schools, consequently stigmatising lower-performing schools, and decided to withdraw from the project. With their withdrawal, the school district management requested their datasets to be deleted and insisted that all knowledge derived from their information should be removed from the model, as they no longer supported the project’s new purposes.
By this time, the project had been running for three years and the AI model was actively used by all participants. Retraining the entire system from scratch was deemed too costly and time-consuming by the project managers, so the project team implemented an alternative strategy to remove the impact of District A’s dataset on the model.
However, after successfully removing the information learned from the School District A dataset, the remaining participants noticed a shift in the model’s behaviour. Some students began to express dissatisfaction with the platform’s feedback, particularly regarding pronunciation exercises. These students felt the platform was being overly critical, incorrectly marking responses as false that they believed were correct. Teachers confirmed that the platform seemed to be marking some students more harshly than others.
The project team’s data scientist investigated further, re-testing the model and asking teachers to provide additional information on the students who felt their answers were unfairly marked. The investigation revealed that these students shared many characteristics with those from the departed School District A, particularly the language spoken at home. It appeared that the AI model was no longer adequately recognising certain accents, which caused it to incorrectly mark some students’ answers, highlighting an unintended consequence of the data removal process. |
Machine unlearning
By Saskia Keskpaik
Machine learning, a subset of artificial intelligence, leverages data and algorithms to enable AI systems to mimic human learning and make predictions on new, similar data without explicit programming for each task. Learning occurs during a training phase, resulting in an AI model that encodes knowledge as weights within a complex system (such as a neural network).
AI systems often involve training data collected from individuals, including sensitive personal information like unique identifiers, behavioural data, and health-related information that may be embedded in the final model that is subsequently deployed.
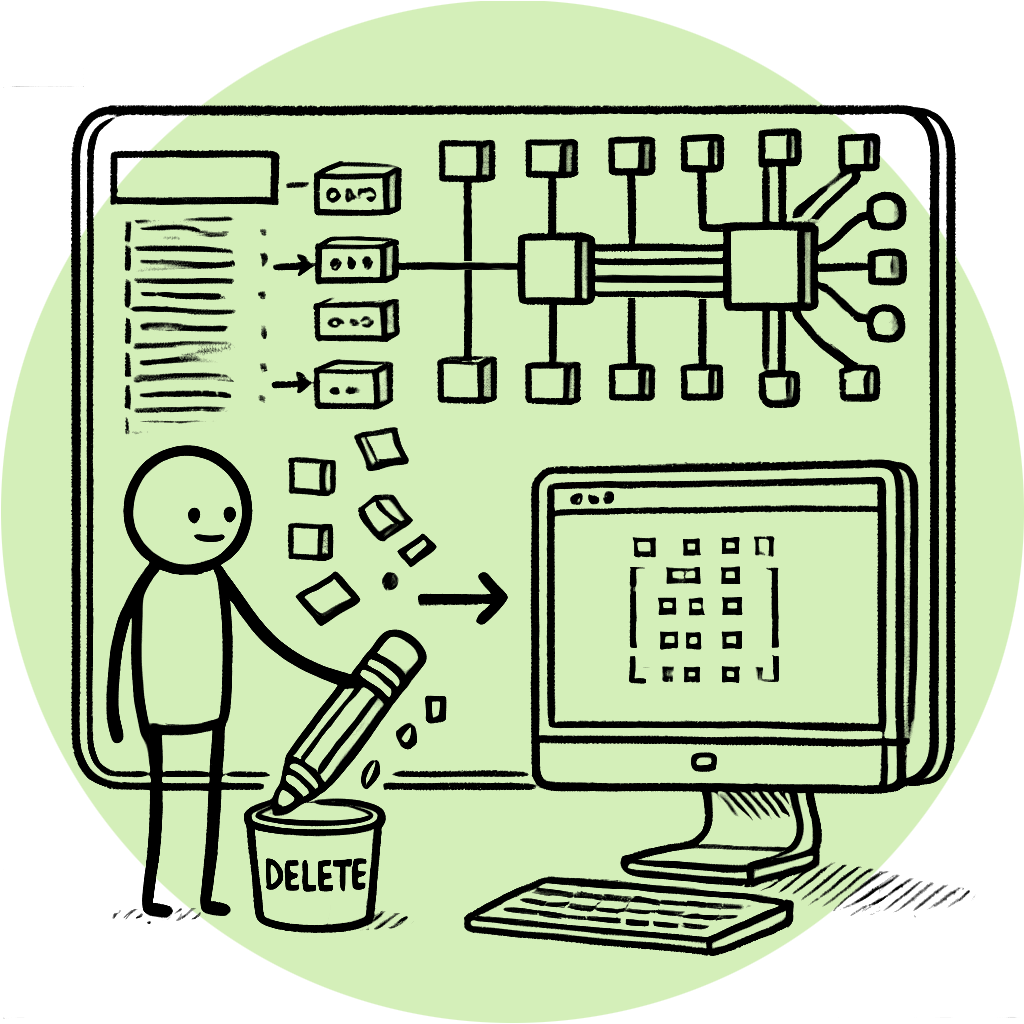
There are many reasons to remove data from a trained system, but the rights of individuals are particularly important when personal data is involved. After a model is trained, an individual might object to the use of their data and request that the machine learning application erase certain personal information used in its training. Other reasons for unlearning include discovering that low-quality data was used during training, leading to errors or biases that harm model performance. Additionally, outdated data may need to be removed to improve the model’s accuracy.
To remove specific data from a trained machine learning model, systems need to eliminate any effect this particular data point or portion of data can have on the extracted features and the model itself - a process known as unlearning.
Unlearning methods can be classified into two types: exact unlearning and approximate unlearning.
Exact unlearning
In exact unlearning, the goal is to remove the influence of specific data points as if they were never part of the training process. This can be achieved by retraining the model from scratch after removing the specific data, but more advanced techniques aim to eliminate the data’s influence without full retraining, making the process faster and less resource-intensive. For instance, training approach labelled as Sharded, Isolated, Sliced, and Aggregated (SISA) involves splitting the training process into sub-models based on pre-divided data subsets. Ensuring that the removal is exact and that no trace of the data remains in the model can be challenging, particularly with complex models.
Approximate unlearning
This approach aims to remove or reduce the influence of specific data points from the model, but with a trade-off in precision. Instead of retraining, the model undergoes updates that diminish the impact of the data to be ‘forgotten’. Techniques such as adjusting model weights or applying correction factors are used. These techniques aim to minimise the influence of unlearned data to an acceptable level while achieving efficient unlearning, thereby reducing both storage and computational costs.
While approximate methods are faster, they may leave residual traces of the data, which can be problematic in sensitive applications.
When an unlearning algorithm modifies the initial model to forget the specified data, the result is an unlearned model, which is then evaluated against different performance metrics[i]. To ensure that the model has genuinely forgotten the requested data and that no information leaks remain, the model undergoes a verification process. This process might involve various tests, including feature injection[ii] and membership inference attacks.[iii] If the model passes verification, it becomes the new model for subsequent tasks such as prediction, recommendation, and inference. If the model fails, retraining with the remaining data (excluding the data to be forgotten) is the only option. However, as noted, this process can be quite costly.
Development status
While some machine unlearning techniques have shown potential in efficiently erasing data without full retraining, the challenge lies in maintaining model accuracy and performance at scale. Current methods are still being refined, and widespread implementation in mainstream AI systems has yet to be realised, making it a developing but crucial area of research.
Currently, most machine unlearning approaches focus on relatively structured training data (e.g., collections of distinct elements or graphs). However, extending these techniques to handle complex data types such as text, speech, images and multimedia is becoming increasingly important, though challenging. Developing multimodal unlearning techniques that consider various data combinations is also crucial for practical applications. Addressing these challenges can expand the applicability of machine unlearning.
Another line of research is to create interactive and interpretable unlearning algorithms that give users fine-grained control over what to remove from a model. For example, users might want to remove only specific sensitive parts of an image or certain words in a text document. This capability could enhance the effectiveness of unlearning techniques to meet user requirements.
A current focus of machine unlearning research is the trade-off between privacy and model utility. Most existing unlearning algorithms use differential privacy, which balances privacy and utility but may fall short in cases of extremely high privacy requirements, such as in medical research settings. Research is now exploring improved methods to limit information disclosure without sacrificing model utility. One approach is information-theoretic, where candidate models are compared to identify the one closest to the truth.
A prominent method in the realm of approximate machine unlearning is the ‘certified removal’ approach, which provides a formal guarantee that data has been successfully and verifiably removed from the model. This approach involves using mathematical proofs or certification methods to ensure that the data’s influence has been entirely eliminated. However, it is not practical for all scenarios because it imposes specific algorithmic constraints and requires complex verification processes.
Ensuring that unlearning is complete and accurate is a complex task, requiring robust verification mechanisms. Ongoing research is also focused on developing frameworks and criteria for assessing the performance of various machine unlearning models. These frameworks are essential for standardising the evaluation process and enabling consistent comparisons between different methods. Standardised comparisons are necessary because one method may be more appropriate than another in certain situations.
Lastly, unlearning, especially in large, complex models, can be resource-intensive. The size and complexity of many machine learning algorithms require considerable energy consumption. As governments emphasise energy conservation and greener practices, finding efficient ways to implement these complex algorithms is becoming increasingly important.
Potential impact on individuals
Machine unlearning can play a significant role in helping individuals exercise their rights under data protection regulations and allowing controllers to have greater control over the associated personal data processing activities.
Another significant impact of machine unlearning is its potential to improve data accuracy and reduce bias, although in some cases, unlearning can also negatively affect model performance if substantial knowledge is erased. By enabling learning systems to forget outdated or erroneous data, unlearning helps maintain the accuracy of the data used in these systems. This, in turn, enhances fairness, as decisions made by machine learning models are based on more accurate and current data.
There is a risk that machine unlearning might also reduce the quality of results produced by learning systems. Removing data can lead to the loss of critical information, resulting in degraded performance and unreliable predictions, ultimately compromising system reliability. Typically, an unlearned model performs worse compared to one retrained on retained data. The degradation can worsen exponentially as more data is unlearned, a phenomenon known as catastrophic unlearning or catastrophic forgetting. Despite efforts to mitigate this through specialised loss functions[iv], preventing catastrophic unlearning remains an ongoing challenge.
Unlearning may also affect the model’s predictions differently across various groups, potentially leading to unfairness. For instance, if the unlearning process disproportionately affects the accuracy of predictions for certain demographic sub-populations, it could introduce new biases or exacerbate existing ones, undermining the fairness of the model.
Machine unlearning necessitates auditability and verification to ensure that personal data has been successfully deleted from the models. This requirement for transparency can increase trust in these systems. When users and regulatory bodies can verify that data has been properly unlearned, it fosters confidence in the privacy practices of the organisations utilising these models.
However, unlearning can be challenging to prove, raising doubts about whether unlearning truly occurred and if their personal data still exists within the model. Furthermore, machine unlearning alone cannot fully guarantee the right to be forgotten. Technical and legal measures such as verifiable proof of unlearning, data ownership verification and audits for potential privacy leaks are necessary to fully enforce this right.
Additionally, unlearning poses risks related to unintentional data disclosure. This process may leave traces that can leak information, including personal data. Models that have undergone unlearning can be subject to attacks, such as membership inference attacks or private information reconstruction attacks, which aim to determine which personal data was unlearned. The difference in model outputs before and after unlearning might inadvertently reveal details about the erased data, compromising privacy. These potential security risks highlight the need for robust mechanisms to ensure that unlearning processes do not introduce new vulnerabilities.
Machine unlearning should not be viewed as a ‘band-aid solution’, but as an integral part of the overall data management and privacy strategy to ensure long-term robustness and trustworthiness in AI systems.
Suggestions for further reading
- Cao, Y., & Yang, J. (2015). Towards Making Systems Forget with Machine Unlearning. 2015 IEEE Symposium on Security and Privacy, 463–480.https://doi.org/10.1109/SP.2015.35
- Guo, C., Goldstein, T., Hannun, A., & Van Der Maaten, L. (2023). Certified data removal from machine learning models. arXiv preprint arXiv:1911.03030.https://arxiv.org/abs/1911.03030
- Sai, S., Mittal, U., Chamola, V., Huang, K., Spinelli, I., Scardapane, S., Tan, Z., & Hussain, A. (2023). Machine Un-learning: An Overview of Techniques, Applications, and Future Directions. Cognitive Computation. https://doi.org/10.1007/s12559-023-10219-3
- Xu, J., Wu, Z., Wang, C., & Jia, X. (2024). Machine Unlearning: Solutions and Challenges. IEEE Transactions on Emerging Topics in Computational Intelligence, 8(3), 2150–2168. https://doi.org/10.1109/TETCI.2024.3379240
[i] Performance metrics - Quantitative measures used to evaluate the effectiveness, accuracy, and efficiency of machine learning models. The metrics help in assessing how well a model performs on specific tasks and guide improvements in model development.
[ii] Feature injection test - Evaluates the effectiveness of an unlearning method. Aims to verify whether the unlearned model has adjusted the weights corresponding to the removed data samples based on data features/attributes.
[iii] Membership inference attack - A type of attack where an adversary queries a trained machine learning model to predict whether or not a particular example was contained in the model's training dataset.
[iv] Loss function - Measures how well a model performs by calculating how far the predicted values are from the actual values during model training.